On an idle Sunday afternoon, I was browsing my Twitter stream, and came across the following tweet which looked of interest:
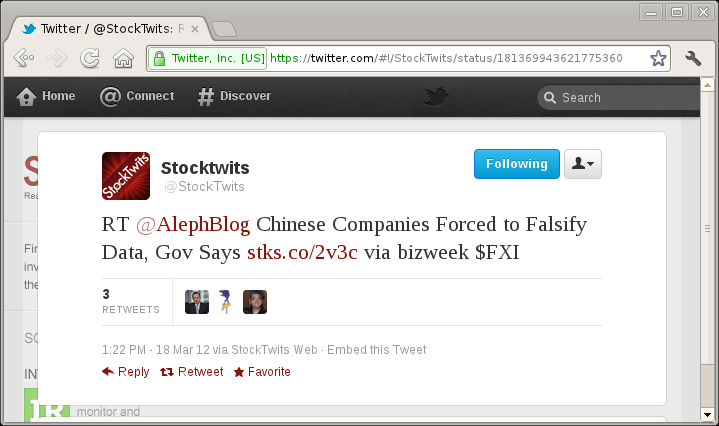 I was actually using the iPad Twitter client at the time, and when I clicked - or rather pressed - on the link, noticed a number of changes in the URL/title bar that appears at the bottom of the app window.
I was actually using the iPad Twitter client at the time, and when I clicked - or rather pressed - on the link, noticed a number of changes in the URL/title bar that appears at the bottom of the app window.
This piqued my interest, so I did a bit more investigation about what was happening on a platform more conducive to my nosiness. Below is a cut-n-paste from the curl session - don't worry about the details, I summarize it further down.
[john@hamburg tmp]$ curl -L -v -v "http://t.co/1mkYnU0v"
* About to connect() to t.co port 80 (#0)
* Trying 199.59.148.12... connected
* Connected to t.co (199.59.148.12) port 80 (#0)
> GET /1mkYnU0v HTTP/1.1
> User-Agent: curl/7.21.3 (x86_64-redhat-linux-gnu) libcurl/7.21.3 NSS/3.13.1.0 zlib/1.2.5 libidn/1.19 libssh2/1.2.7
> Host: t.co
> Accept: */*
>
< HTTP/1.1 301 Moved Permanently
< Date: Sun, 18 Mar 2012 16:41:20 GMT
< Server: hi
< Location: http://stks.co/2v3c
< Cache-Control: private,max-age=300
< Expires: Sun, 18 Mar 2012 16:46:20 GMT
< Content-Length: 0
< Connection: close
< Content-Type: text/html; charset=UTF-8
<
* Closing connection #0
* Issue another request to this URL: 'http://stks.co/2v3c'
* About to connect() to stks.co port 80 (#0)
* Trying 174.129.233.169... connected
* Connected to stks.co (174.129.233.169) port 80 (#0)
> GET /2v3c HTTP/1.1
> User-Agent: curl/7.21.3 (x86_64-redhat-linux-gnu) libcurl/7.21.3 NSS/3.13.1.0 zlib/1.2.5 libidn/1.19 libssh2/1.2.7
> Host: stks.co
> Accept: */*
>
< HTTP/1.1 301 Moved Permanently
< Server: nginx/0.7.65
< Date: Sun, 18 Mar 2012 16:41:20 GMT
< Content-Type: text/html
< Connection: close
< X-Powered-By: PHP/5.3.2-1ubuntu4.9
< Set-Cookie: snowball=6f87bf80-df9c-4bc5-932e-12ff806b0374; expires=Mon, 18-Mar-2013 16:41:20 GMT; path=/; domain=stks.co
< Content-Encoding: none
< Location: http://t.co/tH0MUiYn
< Content-Length: 1
<
* Closing connection #0
* Issue another request to this URL: 'http://t.co/tH0MUiYn'
* About to connect() to t.co port 80 (#0)
* Trying 199.59.148.12... connected
* Connected to t.co (199.59.148.12) port 80 (#0)
> GET /tH0MUiYn HTTP/1.1
> User-Agent: curl/7.21.3 (x86_64-redhat-linux-gnu) libcurl/7.21.3 NSS/3.13.1.0 zlib/1.2.5 libidn/1.19 libssh2/1.2.7
> Host: t.co
> Accept: */*
>
< HTTP/1.1 301 Moved Permanently
< Date: Sun, 18 Mar 2012 16:41:21 GMT
< Server: hi
< Location: http://buswk.co/yGATqD
< Cache-Control: private,max-age=300
< Expires: Sun, 18 Mar 2012 16:46:21 GMT
< Content-Length: 0
< Connection: close
< Content-Type: text/html; charset=UTF-8
<
* Closing connection #0
* Issue another request to this URL: 'http://buswk.co/yGATqD'
* About to connect() to buswk.co port 80 (#0)
* Trying 168.143.174.97... connected
* Connected to buswk.co (168.143.174.97) port 80 (#0)
> GET /yGATqD HTTP/1.1
> User-Agent: curl/7.21.3 (x86_64-redhat-linux-gnu) libcurl/7.21.3 NSS/3.13.1.0 zlib/1.2.5 libidn/1.19 libssh2/1.2.7
> Host: buswk.co
> Accept: */*
>
< HTTP/1.1 301 Moved
< Server: nginx
< Date: Sun, 18 Mar 2012 16:41:21 GMT
< Content-Type: text/html; charset=utf-8
< Connection: keep-alive
< Set-Cookie: _bit=4f661031-00291-0797b-3d1cf10a;domain=.buswk.co;expires=Fri Sep 14 16:41:21 2012;path=/; HttpOnly
< Cache-control: private; max-age=90
< Location: http://www.businessweek.com/news/2012-03-16/chinese-companies-forced-to-falsify-economic-data-bureau-says
< MIME-Version: 1.0
< Content-Length: 197
<
* Ignoring the response-body
* Connection #0 to host buswk.co left intact
* Issue another request to this URL: 'http://www.businessweek.com/news/2012-03-16/chinese-companies-forced-to-falsify-economic-data-bureau-says'
* About to connect() to www.businessweek.com port 80 (#1)
* Trying 77.67.40.33... connected
* Connected to www.businessweek.com (77.67.40.33) port 80 (#1)
> GET /news/2012-03-16/chinese-companies-forced-to-falsify-economic-data-bureau-says HTTP/1.1
> User-Agent: curl/7.21.3 (x86_64-redhat-linux-gnu) libcurl/7.21.3 NSS/3.13.1.0 zlib/1.2.5 libidn/1.19 libssh2/1.2.7
> Host: www.businessweek.com
> Accept: */*
>
< HTTP/1.1 200 OK
< Server: Apache/2.2.9 (Unix) mod_ssl/2.2.9 OpenSSL/0.9.8e-fips-rhel5 mod_jk/1.2.31
< X-Powered-By: Phusion Passenger (mod_rails/mod_rack) 3.0.1
< X-UA-Compatible: IE=Edge,chrome=1
< X-Runtime: 0.316604
< X-Rack-Cache: miss
< Status: 200
< benv: njbweb03
< Content-Type: text/html; charset=utf-8
< Cache-Control: must-revalidate, max-age=1640
< Date: Sun, 18 Mar 2012 16:41:22 GMT
< Transfer-Encoding: chunked
< Connection: keep-alive
< Connection: Transfer-Encoding
<
{ the HTML of the actual page finally gets served from this point }
First off, as I think most techie people know, the link addresses that the Twitter site and apps show aren't actually what they appear to be, they are in fact using Twitter's own t.co link shortening * service. This in turn redirects to the "real" URL, except in a case such as this, the redirect is to StockTwits own shortener.
Which in turn redirects back to a different URL on t.co.
Which then redirects to Business Week's link shortener.
Which only then redirects you to the real page.
i.e. there are four HTTP redirects before you actually get to what you want. When I did some tests with curl'ing the first t.co and then following the redirects, versus getting the page directly, I was finding that the redirects were adding between 1.5 and seconds on average to the overall time taken. (In a few cases it was closer to 6-7 seconds, although this could possibly be down to one of the servers in the chain throttling back multiple requests in a short time period.)
[john@hamburg tmp]$ for X in `seq 10`
do
time curl -s -L --no-sessionid -o /dev/null "http://t.co/1mkYnU0v"
sleep 1
time curl -s -L --no-sessionid -o /dev/null "http://www.businessweek.com/news/2012-03-16/chinese-companies-forced-to-falsify-economic-data-bureau-says"
sleep 1
done
{ results snipped: t.co varied between 1.9s and 7.3s, direct link between 0.2s and 0.9s }
I got similar results from Pingdom - it loaded the page faster, but still had a non-trivial delay from the redirects:
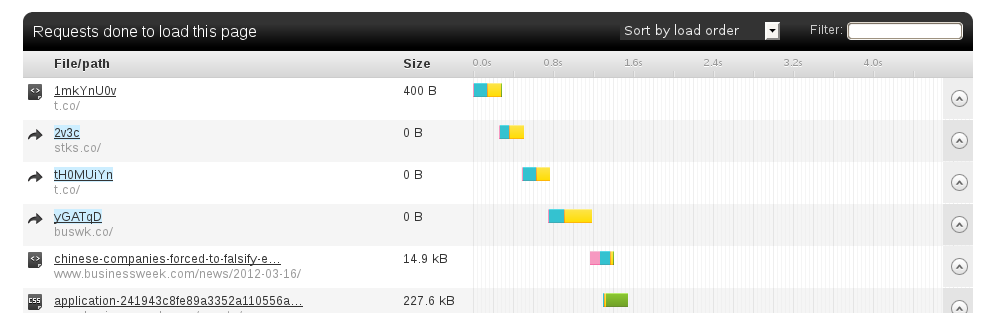 Obviously, my curl tests don't reflect the real browser experience, as they don't show the time taken to load images, CSS, JavaScript etc, but the Pingdom test showed that the redirects took up a second of an overall load time of 4.6 seconds - not a non-trivial delay in my opinion.
Obviously, my curl tests don't reflect the real browser experience, as they don't show the time taken to load images, CSS, JavaScript etc, but the Pingdom test showed that the redirects took up a second of an overall load time of 4.6 seconds - not a non-trivial delay in my opinion.
Given that there have been any number of articles posted and tools made available for analyzing and improving web page load times, it seems crazy to have external services slowing things down - or even breaking on occasions.
Given that all of the redirects in this example were permanent, maybe Twitter should get even more aggressive with t.co, by evaluating redirect chains like this, and just having the t.co link go straight to the final destination. Browsers seem to have been caching HTTP 301s for a few years now, so maybe web services should too?
Footnote: t.co isn't actually shortening the StockTwits link, as the latter is one character shorter:
[john@hamburg tmp]$ echo "http://t.co/1mkYnU0v" | wc -c
21
[john@hamburg tmp]$ echo "http://stks.co/2v3c" | wc -c
20
I guess they're opting to build up a big analytics database of popularly-clicked-links that they'll hope to monetize, over making things better (albeit in a tiny way) for their end users.
 anywhere on this page, and I was mystified by the significance of the icon below the M in Monday, until I noticed it was the same as the one in the host OS taskbar for showing network status - I don't think I would have got it otherwise")
 Note that in the above shot, I'd already reduced some of the boxes that default to double width (such as Weather and Calendar) down to single width. I'm not sure why the "packer" automatically moved some items into the space that was freed when I did that, but hasn't moved Music - the items can be manually dragged, but it seems odd that it sometimes works automatically and sometimes not.
Note that in the above shot, I'd already reduced some of the boxes that default to double width (such as Weather and Calendar) down to single width. I'm not sure why the "packer" automatically moved some items into the space that was freed when I did that, but hasn't moved Music - the items can be manually dragged, but it seems odd that it sometimes works automatically and sometimes not.
 Moving the browser chrome down to the bottom in Metro is a non-issue. Moving the "forward" button to the far right, rather than being adjacent to the "back" button, and losing the "home" & "bookmarks" buttons, are very questionable. But refusing to play Flash content on a machine that has Flash installed and working is absolutely batshit insane.
Moving the browser chrome down to the bottom in Metro is a non-issue. Moving the "forward" button to the far right, rather than being adjacent to the "back" button, and losing the "home" & "bookmarks" buttons, are very questionable. But refusing to play Flash content on a machine that has Flash installed and working is absolutely batshit insane.
 As an avowed Flash-hater, on one level I do want to welcome yet another nail in its coffin. However, this puritanical refusal to do something that the machine/OS/browser is clearly capable of, seems very user-hostile. I was aware that Flash and other plug-ins were not going to be available in some versions of Windows 8, but I'd assumed it was just going to be the ARM/mobile versions, which makes perfect sense. I guess that MS have decided though that they want to try to have a consistent experience across all Metro platforms, which is admirable in some respects. But given the failure though of non-iPad tablets, I would expect the ARM/mobile part of the overall Win8 user base to be a drop in the ocean for the foreseeable future, so making the experience worse for the 9x% of people on desktop/laptop machines just so the tiny fraction of people on ARM/mobile don't feel left out, strikes me as misguided.
As an avowed Flash-hater, on one level I do want to welcome yet another nail in its coffin. However, this puritanical refusal to do something that the machine/OS/browser is clearly capable of, seems very user-hostile. I was aware that Flash and other plug-ins were not going to be available in some versions of Windows 8, but I'd assumed it was just going to be the ARM/mobile versions, which makes perfect sense. I guess that MS have decided though that they want to try to have a consistent experience across all Metro platforms, which is admirable in some respects. But given the failure though of non-iPad tablets, I would expect the ARM/mobile part of the overall Win8 user base to be a drop in the ocean for the foreseeable future, so making the experience worse for the 9x% of people on desktop/laptop machines just so the tiny fraction of people on ARM/mobile don't feel left out, strikes me as misguided.
 anywhere on this page, and I was mystified by the significance of the icon below the M in Monday, until I noticed it was the same as the one in the host OS taskbar for showing network status - I don't think I would have got it otherwise")
")


{kind=link}